

“Science is not only a discipline of reason but also of passion and love” - Stephen Hawking
![]()
![]()
![]()
![]()
Research Interest
Large Language Models (LLMs), Multimodal LLMs, Frontier / Foundation Models, Vision and Language, Natural Language Processing (NLP), Conversational AI, Multimodal Dialog
I am particularly interested in Deep Learning and its interdisciplinary applications (V&L). Check out Github for my latest activity.
Fun fact: My Erdős number is 4. See here.
Quick background
Current: Staff Research Scientist at Krutrim AI - building foundation models for India
Previous: Postdoc at MILA | ServiceNow Research | University of Montreal (HEC Montreal).
Advised by: Prof. Chris Pal (MILA, ServiceNow), Dr. Laurent Charlin (MILA) and Dr. Issam Laradji (ServiceNow)
Past: @PulselabsAI | @AdobeResearch | @GSoC | @XRCE | @TrulyMadly | @IITDelhi
Past Research Challenges: 007 @ English-to-lowres Multimodal Machine Translation Task’ 24 | Alana @ Alexa Prize Socialbot Challenge’ 18 | Pikabot @ Visual Dialog Challenge’ 18 | NLE @ E2E NLG Challenge’ 17
Bio
My research interests lie in training frontier models while I am keenly interested in visual grounding (symbol grounding) and context modeling (communicative grounding) in multi-modal visual conversational agents. I am interested to build machines that can see and talk. My research interests broadly span multi-modal representation and transfer learning for vision and language problems. Previously I also explored Natural Language Generation for data-to-text and knowledge grounded multi-modal dialog response generation. I was an integral part of Team Alana - finalists to Amazon’s Alexa Prize Socialbot Grand Challenge 2018. My submission was also the runner-up for the Visual Dialog Challenge 2018 (Pikabot) and E2E NLG Challenge 2017 (NLE). I am an active blogger, often contributing to open-source repositories for the democratization of AI. I also co-organized the Workshop on Evaluating NLG Evaluation (EvalNLGEval at INLG’20) and Workshop on Human Evaluation of NLP Systems (HumEval at EACL’21); served on the Program Committee for NeurIPS and ACL workshops; reviewed for NLP/AI conferences (NeurIPS, ICML, ICLR, ACL, COLING), and published at top NLP conferences such as CVPR, ICLR, ACL, NeurIPS, EACL, EMNLP, INLG, SIGDial.
Visitors on the page - Thank you for visiting!
Recreational
Where are the banner images from?
In case you are wondering, yes I have been to all these places! Yes, we own the copyright of these pictures! The images are from Death Valley, Yosemite (US), Northen lights in Iceland, Malta, Hawaii, Croatia, Vienna, Edinburgh.
Countries visited
I have been to 4 continents and 37 countries.
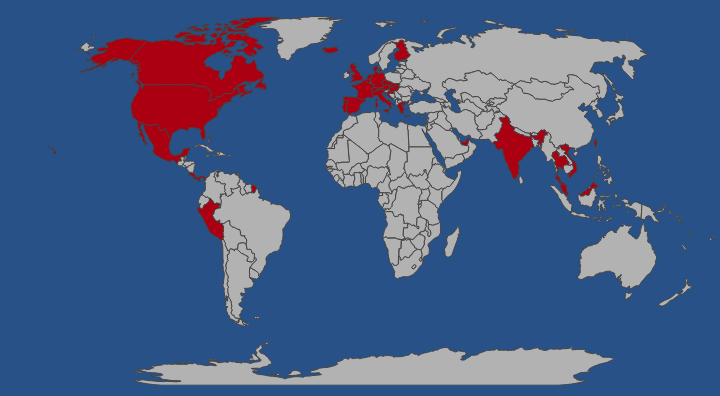
visited 37 states (17.05%)
Create your own visited map of The World

visited 20 states (55.56%)
Try Create your own visited map of Indian states